6 Tutorial: Text manipulation with stringr
After working through Tutorial 6, you’ll…
- understand the concept of string patterns and regular expressions
- know how to search for string patterns
6.1 What’s stringr?
The stringr package is another package of the tidyverse family,
i.e., it comes pre-installed with the tidyverse. The package offers a
neat set of functions that makes working with strings really simple for
beginners. Therefore, stringr is a good place to start getting into
text data management. A string is a data type that is used to represent
text rather than numbers.
6.2 Working with strings
First, let’s create a vector that contains some strings and print the vector to the console!
fruits <- c("banana", "apple", "pear", "strawberry", "raspberry", "kiwi", "rhubarb")
fruits## [1] "banana" "apple" "pear" "strawberry" "raspberry"
## [6] "kiwi" "rhubarb"First, we want to know how long each of these strings is, i.e., how many
characters the elements of the fruits vector contain. We will use the
str_length() function.
str_length(fruits)## [1] 6 5 4 10 9 4 7That was easy. Next, we want to join multiple strings into a single
string. We will use the str_c function.
str_c(fruits, collapse = " and ")## [1] "banana and apple and pear and strawberry and raspberry and kiwi and rhubarb"# If collapse is not NULL, it will be inserted between elements of the result, here: andYou can also change the order of the str_c function:
str_c("My favourite fruit is: ", fruits, collapse = NULL) ## [1] "My favourite fruit is: banana" "My favourite fruit is: apple"
## [3] "My favourite fruit is: pear" "My favourite fruit is: strawberry"
## [5] "My favourite fruit is: raspberry" "My favourite fruit is: kiwi"
## [7] "My favourite fruit is: rhubarb"Let’s say, we want to extract substrings from a character vector. For
example, we only want to keep the second to fourth letter of each
string. We can use the str_sub function to achieve that.
str_sub(fruits, start = 2, end = 4) ## [1] "ana" "ppl" "ear" "tra" "asp" "iwi" "hub"6.3 Working with string patterns
Often we want to search for certain string patterns in a text document. String patterns are character sequences (for instance, letter, numbers, or special characters). Let’s assume for a second that we have misspelled one of our fruits (banana, we have switched the na letters to an).
misspelled_fruits <- c("baanan", "apple", "pear", "strawberry", "raspberry", "kiwi", "rhubarb")It would be really great if we could search for the string pattern
“an” and replace it with the string pattern “na” automatically,
wouldn’t it? Well, stringroffers some functions to do just that. For
example, str_detect() tells you if there’s any match to the pattern.
str_detect(misspelled_fruits, "an")## [1] TRUE FALSE FALSE FALSE FALSE FALSE FALSENow we know that there is one word that contain letters that match the
“an” pattern. We have a misspelling! What is that word? str_subset()
extracts the matching strings, so that we can find out.
str_subset(misspelled_fruits, "an")## [1] "baanan"Of course, it’s banana. But how many times has “an” been misspelled
in banana? Just once? Let’s find out with str_count(, which counts
the number of patterns in each string.
str_count(misspelled_fruits, "an")## [1] 2 0 0 0 0 0 0Two times! Let’s fix that with the str_replace function.
misspelled_fruits <- str_replace(misspelled_fruits, "anan", "nana")
misspelled_fruits## [1] "banana" "apple" "pear" "strawberry" "raspberry"
## [6] "kiwi" "rhubarb"Perfect! We have fixed our misspelled fruits. However, keep in mind that pattern correction can mess up your string pretty badly if you are not cautious. Therefore, you should always explore your strings very thoroughly before replacing any string patterns. For example, let’s see what our pattern detection will uncover if our misspelled fruits would contain an additional orange, which has been spelled correctly:
misspelled_fruits <- c("baanan", "apple", "pear", "strawberry", "raspberry", "kiwi", "rhubarb", "orange")
str_detect(misspelled_fruits, "an")## [1] TRUE FALSE FALSE FALSE FALSE FALSE FALSE TRUENow, str_detect() matches two words with the “an” pattern, but the
latter is not a misspelling! So always be careful!
As a final lesson, you can also split a string into multiple strings
based on certain string patterns using the str_split()function:
cs_fruits <- c("banana, apple, pear, strawberry, raspberry, kiwi, rhubarb, orange")
str_split(cs_fruits, ",")## [[1]]
## [1] "banana" " apple" " pear" " strawberry" " raspberry"
## [6] " kiwi" " rhubarb" " orange"6.4 Working with regular expressions
Often, we want to match more complicated string patterns than a simple “an”. For example, we might wish to detect all strings in our text document that do not start with “RT”, because “RT” at the beginning of a string implies a retweet rather than an original tweet when analyzing Twitter data. Arguably, we are often not really interested in analyzing retweets (but sometimes we are, it depends on what you want to analyze).
To search and match complex string patterns, we need regular expressions. Regular expressions (short: regex) are a concise language for describing patterns of text. Regex should not be taken literally, but have a non-literal meaning.
6.4.1 Anchors, alternates, and quantifiers
Let’s keep working with our (non-misspelled) fruits vector to display
what regex can do. We will first learn what “anchors” are. Anchors are used to match
the beginning or end of a string, i.e., they denote the start or end of a pattern and are usually used in combination with other patterns. First, let’s look for all strings that start with the
letter b using the ^ (start of string) anchor.
str_detect(fruits, "^b") # ^ stands for "start of string", i.e. we are matching for strings that start with the letter b## [1] TRUE FALSE FALSE FALSE FALSE FALSE FALSEThat’s on point because only our first entry, banana, starts with b
and str_detect() matched that correctly! With a similar approach, you
can find all fruits that end with the letter b:
str_detect(fruits, "b$") # $ stands for "end of string", i.e. we are matching for strings that end with the letter b## [1] FALSE FALSE FALSE FALSE FALSE FALSE TRUEAgain, we have a perfect match of the only fruit that ends with the
letter b: rhubarb. Please, note the difference to not matching these
two regexes (^ and $), but the simple string pattern “b”:
str_detect(fruits, "b") # matches all strings that contain the letter b at any place## [1] TRUE FALSE FALSE TRUE TRUE FALSE TRUEThis has matched banana, strawberry, raspberry, and rhubarb, because all
of these fruits contain a letter b at some place. Finally, you should
also not confuse “^b” with “[^b]”, because [^] stands for
“anything but” in regex language.
fruits <- c("banana", "apple", "pear", "strawberry", "raspberry", "kiwi", "rhubarb", "b", "bbb")
str_detect(fruits, "[^b]") # matches all strings that contain any letters different from b(s)## [1] TRUE TRUE TRUE TRUE TRUE TRUE TRUE FALSE FALSENext, let’s look at “alternates” in regex. Alternates are used to match multiple characters in a single position. They are specified in square brackets, with a list of characters that could be matched. For example, the regular expression “[bc]ow” will match any string that starts with b, or c, followed by ow. This means it will match both bow and cow.
Let’s look at our fruits again and learn about the very powerful “match any one of” regex [].
We will now try to find all the fruits that contain the letter b or the letter e at any position of the string.
fruits <- c("banana", "apple", "pear", "strawberry", "raspberry", "kiwi", "rhubarb")
str_detect(fruits, "[be]") # matches all strings that contain either the letter b or the letter e## [1] TRUE TRUE TRUE TRUE TRUE FALSE TRUEOur regex has managed to match all strings that contain either the
letter b or the letter e, which leaves only kiwi to be FALSE. Next, we
can match all fruits that contain letters that range between s to w
in the ABC. We will need to use the range operator [-]:
str_detect(fruits, "[s-w]") # matches all strings that contain either the letter s, t, u, v, or, w## [1] FALSE FALSE FALSE TRUE TRUE TRUE TRUEAgain, we have a perfect match! The str_detect has successfully
matched “strawberry”, “raspberry”, “kiwi”, and “rhubarb”. Next, we might
want to match all fruits that contain more than one r, i.e., we want
to match strawberry and raspberry, but not pear. This is where the
? operator (zero or one) * operator (zero or more), the + operator
(one or more), and the {n} operator (exactly n) come in handy. These regex are called “quantifiers” and are used to specify how many of the preceding characters should be matched in a string.
str_detect(fruits, "r?") # matches all strings that contain zero or one rs## [1] TRUE TRUE TRUE TRUE TRUE TRUE TRUEstr_detect(fruits, "r*") # matches all strings that contain zero or more rs## [1] TRUE TRUE TRUE TRUE TRUE TRUE TRUEstr_detect(fruits, "r+") # matches all strings that contain one or more rs --> this grabs pear as well, not there yet!## [1] FALSE FALSE TRUE TRUE TRUE FALSE TRUEstr_detect(fruits, "r{2}") # matches all strings that contain exactly two rs --> this grabs only the berries, yeah!## [1] FALSE FALSE FALSE TRUE TRUE FALSE FALSEThis looks great! We now know what what anchors, alternates, and quantifiers in regex are!
6.4.2 Look arounds and groups
Another useful type of regex are “look arounds” and “groups”. Look arounds are used to match patterns before or after a certain character or pattern, and groups are used to group elements of a pattern and specify the order in which they should be evaluated.
One powerful loook around regex is ?=, wich means “followed by” in regex language. For example, a(?=c) will match any a that is being followed by c, i.e., it will match words like “account” or “accurate”. Let’s try to grab all the berries again, but this time we won’t use a quantifier regex, but a look around.
str_detect(fruits, "e(?=r)") # matches all strings that contain an e followed by an r## [1] FALSE FALSE FALSE TRUE TRUE FALSE FALSEOnce again, we detect only the two berries in our fruits vector and ignore the pear. It’s just another way of reaching the same goal. Pro tip: You can also negate the “followed by” regex with a ! turning it into a “not followed by” (because ! is the universal negation symbol; do you remember how ! negates filters in dplyr, e.g., filter(gender != “male”)?). For example:
str_detect(fruits, "e(?!r)") # matches all strings that contain an e not followed by an r## [1] FALSE TRUE TRUE FALSE FALSE FALSE FALSEFinally, we can use the “preceded by” regex: ?<=. Similar to “followed by”, it is used to find a pattern that is preceded by a specific string or character. Let’s match our berries again, but let’s use the “preceeded by” regex instead of the “followed by” regex.
str_detect(fruits, "(?<=e)r") # matches all strings that contain an r preceeded by an e## [1] FALSE FALSE FALSE TRUE TRUE FALSE FALSEOf course, you could also negate this into “not preceeded by” with the help of !:
str_detect(fruits, "(?<!e)r") # matches all strings that contain an r that is not preceeded by an e## [1] FALSE FALSE TRUE TRUE TRUE FALSE TRUEFinally, let’s turn to “groups”, which are used to group elements of a pattern and specify the order in which they should be evaluated.
str_detect(fruits, "(e|a)r") # matches all strings that contain an e or an a which are followed by an r## [1] FALSE FALSE TRUE TRUE TRUE FALSE TRUEIf you remember “alternates” regex from above, you could also write this expression this way:
str_detect(fruits, "[ea]r") # matches all strings that contain an e or an a which are followed by an r## [1] FALSE FALSE TRUE TRUE TRUE FALSE TRUEHowever, groups can become handy if you need to chain multiple groups for complex patterns. This is very advanced stuff, but I wanted to let you know that it exists.
This was a lot, so here comes an overview / summary of all the regex (screenshot of the stringr cheat sheet):
| Screenshot of anchors, alternates, quantifiers, look arounds, and groups (stringr cheat sheet): |
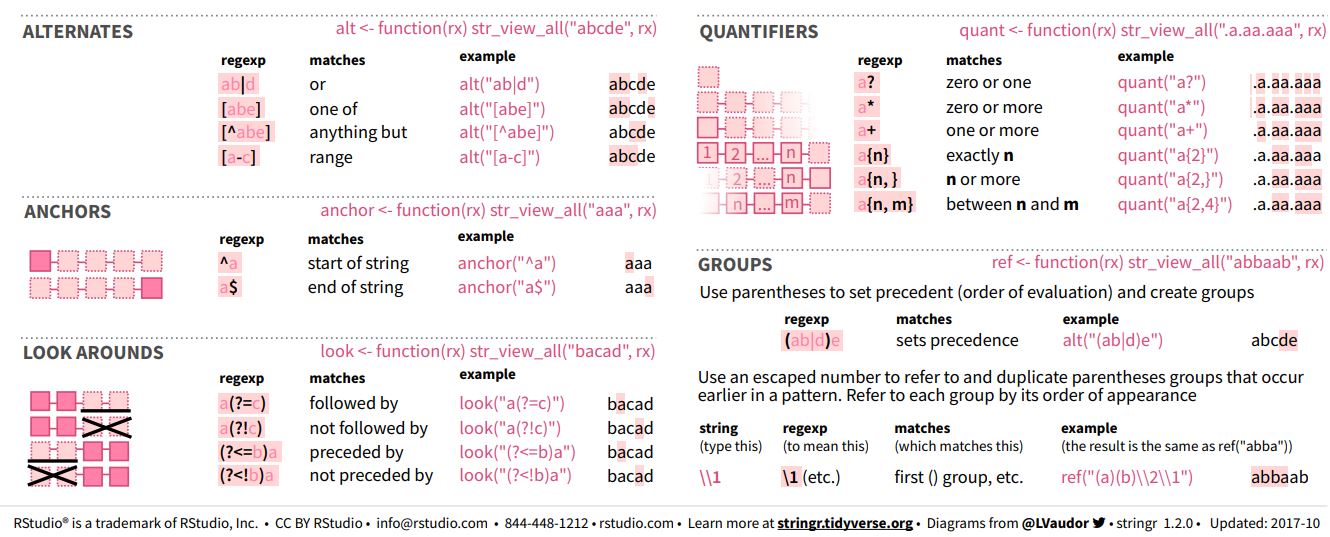 |
6.4.3 Match specific types of characters
There is one last thing I would like to teach you. It’s how to match specific types of characters (e.g., numbers, space symbols, etc.). Let’s first change our fruits vector. I’ll add some numbers, spaces, and slashes.
fruits <- c("ban/ana", "apple", "pear2", "strawberry ", "r0spberry", "k1w1", "rhubarb")Here comes an overview over the types of characters that you can match and how to address them:
| Screenshot of types of characters that can be matched in stringr (stringr cheat sheet): |
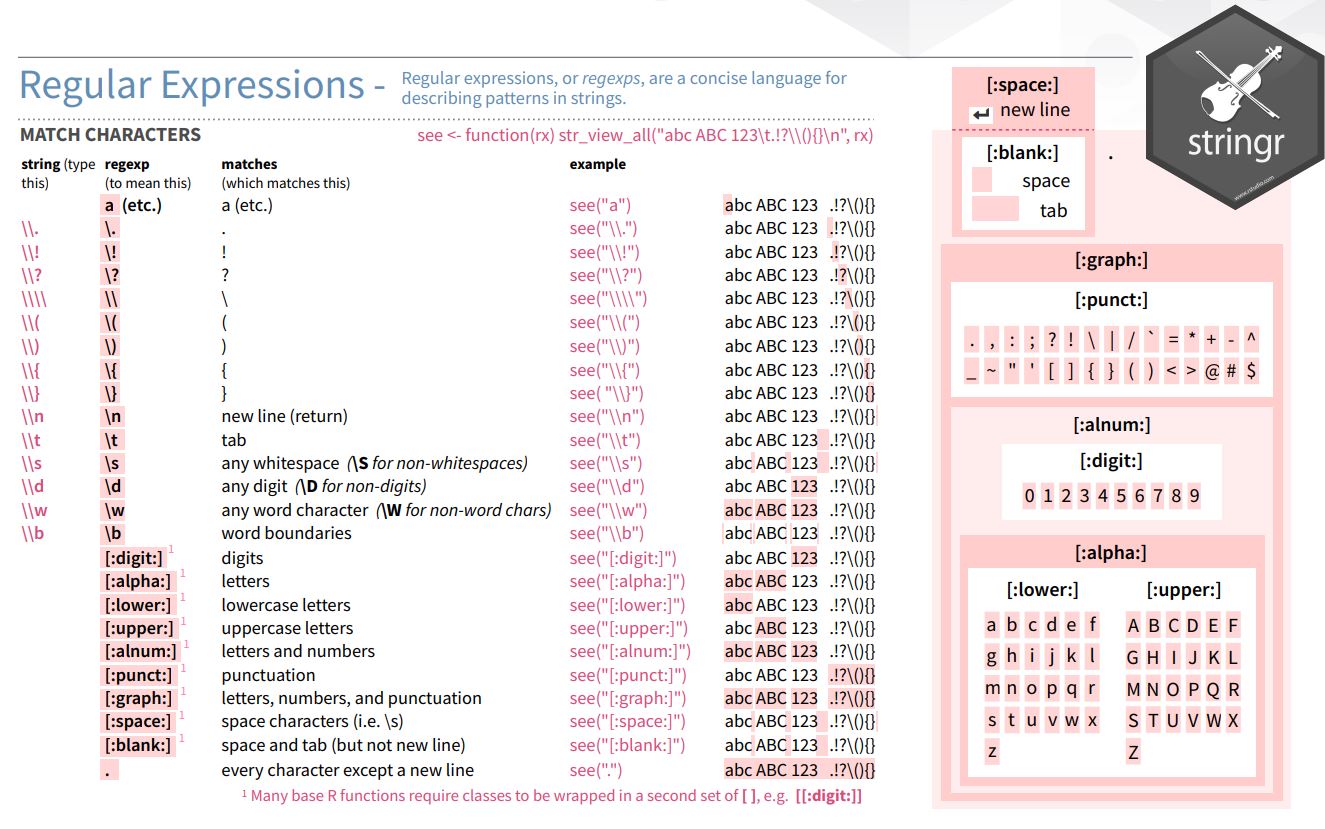 |
Let’s try to detect strings that contain a number, i.e., [:digit:].
str_detect(fruits, "[:digit:]") # matches all strings that contain a number## [1] FALSE FALSE TRUE FALSE TRUE TRUE FALSELet’s try to detect strings that contain a forwardslash /.
str_detect(fruits, "[:punct:]") # matches all strings that contain a punctuation symbol, such as a forwardslash: /## [1] TRUE FALSE FALSE FALSE FALSE FALSE FALSEFinally, we can detect all fruits that are written with a space symbol:
str_detect(fruits, "[:space:]") # matches all strings that contain a space symbol## [1] FALSE FALSE FALSE TRUE FALSE FALSE FALSEFinished! Repeat and practice these commands and you will become a real expert on regular expressions! This tutorial provided an in-depth overview of regular expressions, with only a very few aspects left to explore. If you feel like you need to look up some regular expressions, you can find them in this awesome stringr cheat sheet.
6.5 Take-Aways
- String patterns & RegEx: String patterns are sequences of characters; regular expressions are a type of abstract, generalized string pattern used to match or detect other string patterns in texts.
- Important regular expressions: Anchors, alternates, quantifiers, look arounds and groups. The best overview of all regex options can be found in the stringr cheat sheet.
6.6 Additional tutorials
You still have questions? The following tutorials, books, & tools may help you:
Now let’s see what you’ve learned so far: Exercise 5: Test your knowledge.