6 Tutorial: Text manipulation with stringr
After working through Tutorial 6, you’ll…
- understand the concept of string patterns and regular expressions
- know how to search for string patterns
6.1 What’s stringr?
The stringr package is another package of the tidyverse family,
i.e., it comes pre-installed with the tidyverse. The package offers a
neat set of functions that makes working with strings really simple for
beginners. Therefore, stringr is a good place to start getting into
text data management. A string is a data type that is used to represent
text rather than numbers.
6.2 Working with strings
Let’s create a vector containing some email addresses and print them to the console.
emails <- c("mark@example.com", "john@example.com", "lisa@example.org", "peter@example.net", "jane@example.co.uk", "tim@example.edu", "emmajay@example.gov")
emails## [1] "mark@example.com" "john@example.com" "lisa@example.org"
## [4] "peter@example.net" "jane@example.co.uk" "tim@example.edu"
## [7] "emmajay@example.gov"We can use the str_length() function to find out how many characters each email address contains.
## [1] 16 16 16 17 18 15 19That was easy. Next, we want to join multiple strings into a single
string. We will use the str_c() function.
## [1] "mark@example.com and john@example.com and lisa@example.org and peter@example.net and jane@example.co.uk and tim@example.edu and emmajay@example.gov"You can also change the order of the str_c function:
## [1] "My favourite correspondent is: mark@example.com"
## [2] "My favourite correspondent is: john@example.com"
## [3] "My favourite correspondent is: lisa@example.org"
## [4] "My favourite correspondent is: peter@example.net"
## [5] "My favourite correspondent is: jane@example.co.uk"
## [6] "My favourite correspondent is: tim@example.edu"
## [7] "My favourite correspondent is: emmajay@example.gov"If we want to extract substrings from a character vector, for example, keeping only the user part of each email address, we can use the str_sub() function.
## [1] "mark" "john" "lisa" "peter" "jane" "tim" "emmajay"
## [8] "mark" "john" "lisa" "peter" "jane" "tim" "emmajay"6.3 Working with string patterns
Often we want to search for certain string patterns in a text document. String patterns are character sequences (for instance, letter, numbers, or special characters). Suppose we have some email addresses where ‘@’ was wrongly replaced with ‘#’.
wrong_emails <- c("mark#example.com", "john@example.com", "lisa@example.org", "peter@example.net", "jane@example.co.uk", "tim@example.edu", "emmajay@example.gov")We can search for the string pattern “#” and replace it with “@” automatically. Let’s first identify the emails that contain ‘#’ using str_detect().
## [1] TRUE FALSE FALSE FALSE FALSE FALSE FALSEWe can extract the email addresses that contain ‘#’ using str_subset().
## [1] "mark#example.com"We can fix the wrong email addresses using the str_replace() function.
## [1] "mark@example.com" "john@example.com" "lisa@example.org"
## [4] "peter@example.net" "jane@example.co.uk" "tim@example.edu"
## [7] "emmajay@example.gov"As a final step, we can split an email address into user and domain parts based on the ‘@’ character using the str_split() function:
## [[1]]
## [1] "mark" "example.com"
##
## [[2]]
## [1] "john" "example.com"
##
## [[3]]
## [1] "lisa" "example.org"
##
## [[4]]
## [1] "peter" "example.net"
##
## [[5]]
## [1] "jane" "example.co.uk"
##
## [[6]]
## [1] "tim" "example.edu"
##
## [[7]]
## [1] "emmajay" "example.gov"6.4 Working with regular expressions
Often, we want to match more complicated string patterns than a simple “#”. For example, we might wish to detect all strings in our mail list that do start with “L”, because we want to email those people.
To search and match complex string patterns, we need regular expressions. Regular expressions (short: regex) are a concise language for describing patterns of text. Regex should not be taken literally, but have a non-literal meaning.
6.4.1 Anchors, alternates, and quantifiers
Let’s search for all email addresses that start with the letter ‘j’. To do this, we will first learn what “anchors” are. Anchors are used to match
the beginning or end of a string, i.e., they denote the start or end of a pattern and are usually used in combination with other patterns. First, let’s look for all strings that start with the
letter j using the ^ (start of string) anchor.
str_detect(emails, "^j") # ^ stands for "start of string", i.e. we are matching for strings that start with the letter j## [1] FALSE TRUE FALSE FALSE TRUE FALSE FALSETo find all emails that end with “.com”:
str_detect(emails, "com$") # $ stands for "end of string", i.e. we are matching for strings that end with the letters com## [1] TRUE TRUE FALSE FALSE FALSE FALSE FALSEPlease, note the difference to not matching these two regexes (^ and $), but the simple string pattern “j”:
## [1] FALSE TRUE FALSE FALSE TRUE FALSE TRUEFinally, you should also not confuse “^j” with “[^j]”, because [^] stands for “anything but” in regex language.
## [1] TRUE TRUE TRUE TRUE TRUE TRUE TRUENext, let’s look at “alternates” in regex. Alternates are used to match multiple characters in a single position. They are specified in square brackets, with a list of characters that could be matched. For example, the regular expression “[mj]ohn” will match any string that starts with m, or j, followed by ohn. This means it will match both mohn and john.
Let’s look at our fruits again and learn about the very powerful “match any one of” regex [].
We will now try to find all the emails that contain the letter m or the letter j at any position of the string.
## [1] TRUE TRUE TRUE TRUE TRUE TRUE TRUENext, we can match all emails that contain letters that range between p to z in the ABC. We will need to use the range operator [-]:
## [1] TRUE TRUE TRUE TRUE TRUE TRUE TRUEThe ? operator (zero or one) * operator (zero or more), the + operator
(one or more), and the {n} operator (exactly n) are also handy. These regex are called “quantifiers” and are used to specify how many of the preceding characters should be matched in a string.
## [1] TRUE TRUE TRUE TRUE TRUE TRUE TRUE## [1] TRUE TRUE TRUE TRUE TRUE TRUE TRUEstr_detect(emails, "r+") # matches all strings that contain one or more as --> this grabs pear as well, not there yet!## [1] TRUE FALSE TRUE TRUE FALSE FALSE FALSELastly, let’s find all emails that contain exactly two a’s:
## [1] FALSE FALSE FALSE FALSE FALSE FALSE FALSEThis looks great! We now know what what anchors, alternates, and quantifiers in regex are!
6.4.2 Look arounds and groups
Another useful type of regex are “look arounds” and “groups”. Look arounds are used to match patterns before or after a certain character or pattern, and groups are used to group elements of a pattern and specify the order in which they should be evaluated.
We can leverage look arounds to find certain characters or patterns in our emails. For example, let’s say we want to find all emails where the letter ‘a’ is immediately followed by the letter ‘c’. This is where the “followed by” regex (?=) comes in.
## [1] FALSE FALSE FALSE FALSE FALSE FALSE FALSEAlternatively, we can use a “not followed by” look around (?!). For instance, let’s find all emails where ‘a’ is not followed by ‘c’:
## [1] TRUE TRUE TRUE TRUE TRUE TRUE TRUEAnother useful look around is “preceded by” (?<=). This look around finds patterns that are preceded by a specific string or character. As an example, we can find all emails where ‘r’ is preceded by ‘e’:
## [1] FALSE FALSE FALSE TRUE FALSE FALSE FALSEWe can also negate this into “not preceeded by” with the help of !:
str_detect(emails, "(?<!e)r") # matches all strings that contain an 'r' that is not preceeded by an 'e'## [1] TRUE FALSE TRUE FALSE FALSE FALSE FALSENext, let’s discuss “groups”. These are used to group elements of a pattern and specify the order in which they should be evaluated.
## [1] TRUE FALSE FALSE TRUE FALSE FALSE FALSERemember the “alternates” regex we discussed above? We can also use it here:
str_detect(emails, "[ea]r") # matches all strings that contain an 'e' or an 'a' which are followed by an 'r'## [1] TRUE FALSE FALSE TRUE FALSE FALSE FALSEHowever, groups can become handy if you need to chain multiple groups for complex patterns. This is more advanced, but it’s worth knowing about.
This was a lot, so here comes an overview / summary of all the regex (screenshot of the stringr cheat sheet):
| Screenshot of anchors, alternates, quantifiers, look arounds, and groups (stringr cheat sheet): |
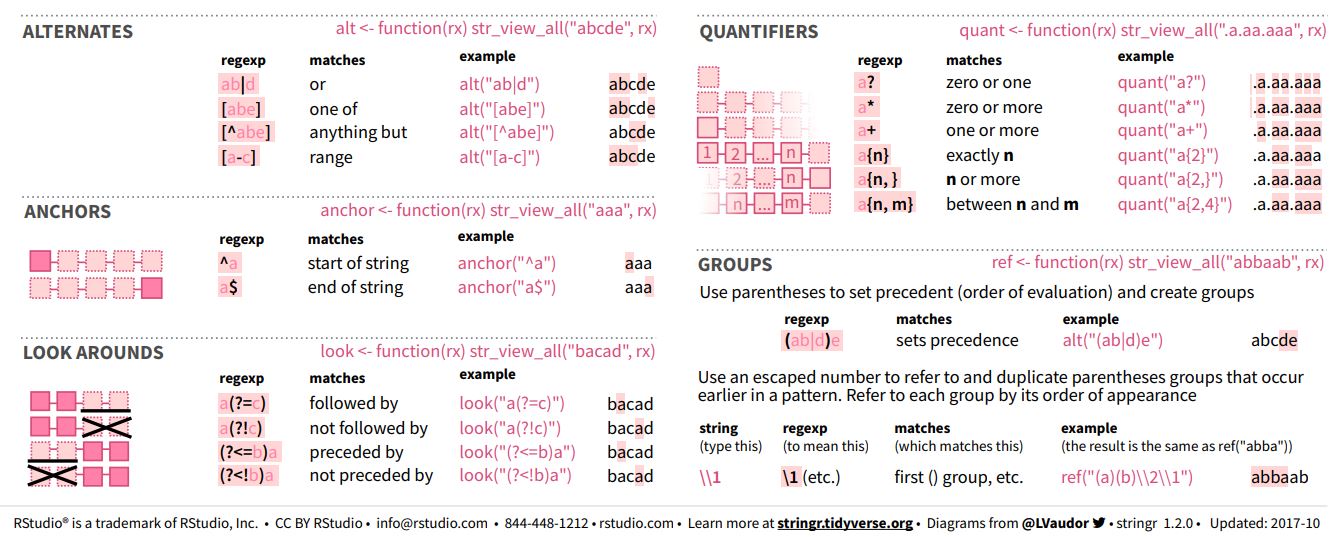 |
6.4.3 Match specific types of characters
There is one last thing I would like to teach you. It’s how to match specific types of characters (e.g., numbers, space symbols, etc.):
## [1] FALSE FALSE FALSE FALSE FALSE FALSE FALSEWe can also detect email addresses that falsely contain a space symbol:
## [1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE| Screenshot of types of characters that can be matched in stringr (stringr cheat sheet): |
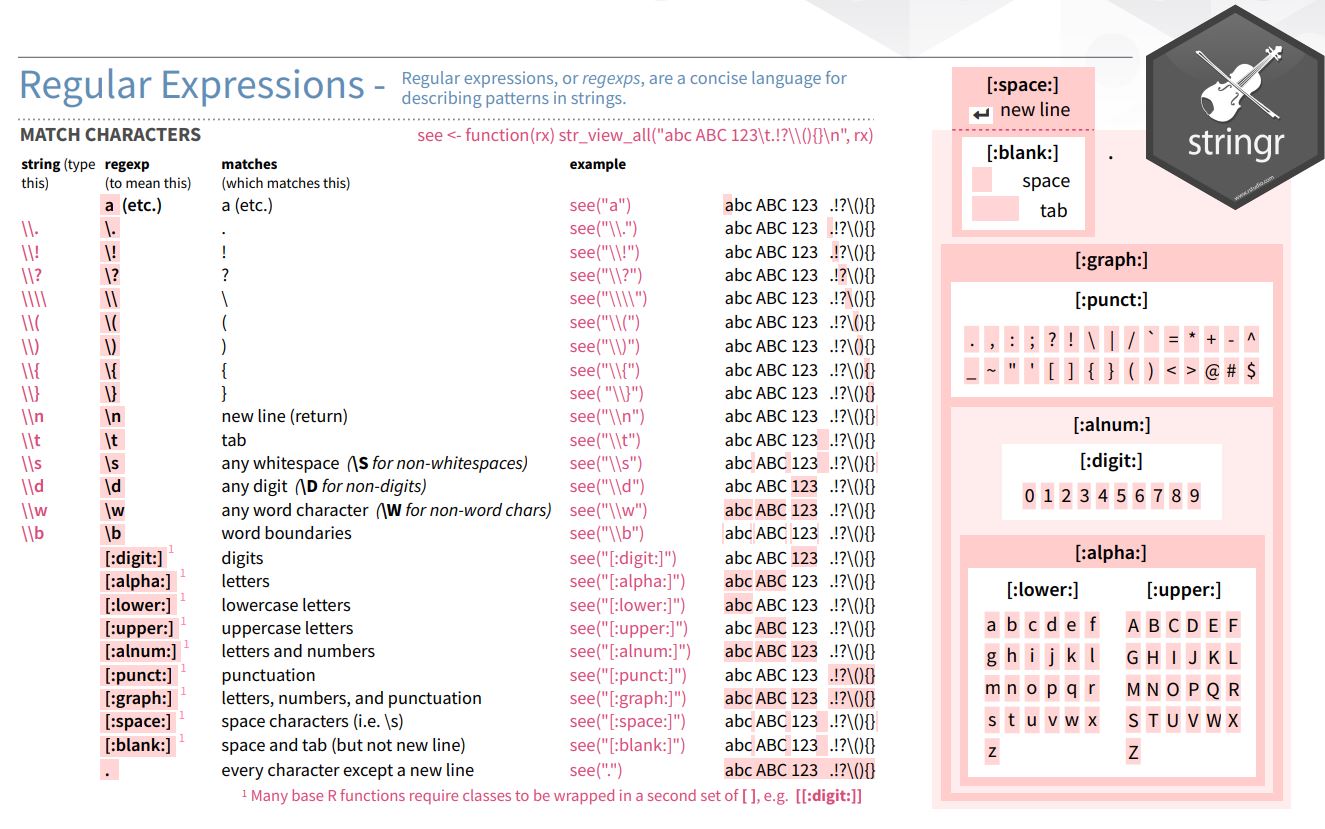 |
Finished! Repeat and practice these commands and you will become a real expert on regular expressions! This tutorial provided an in-depth overview of regular expressions, with only a very few aspects left to explore. If you feel like you need to look up some regular expressions, you can find them in this awesome stringr cheat sheet.
6.5 Take-Aways
- String patterns & RegEx: String patterns are sequences of characters; regular expressions are a type of abstract, generalized string pattern used to match or detect other string patterns in texts.
- Important regular expressions: Anchors, alternates, quantifiers, look arounds and groups. The best overview of all regex options can be found in the stringr cheat sheet.